ぱぱネット(仮)
2010-03-01 Amazon EC2/S3のすべて [長年日記]
_ [読書] Amazon EC2/S3のすべて
 クラウド Amazon EC2/S3のすべて~実践者から学ぶ設計/構築/運用ノウハウ~ (ITpro BOOKs)(並河祐貴/安達輝雄/ITpro/日経SYSTEMS)
クラウド Amazon EC2/S3のすべて~実践者から学ぶ設計/構築/運用ノウハウ~ (ITpro BOOKs)(並河祐貴/安達輝雄/ITpro/日経SYSTEMS)
|
中々良い本でした。
知ってる人は知っているだろうけど、Amazon Web Serviceのオンラインドキュメントは全て英文。 大変わかりにくい。「お前の英語力が足らないからだ!」というのは、ハイごもっとも。でも、 サービス全容を俯瞰でできる図さえない のはどうなの....と常々思っていた。 これはAmazon一般のアカウントサービスなどにも言えるよね。 Yahooや楽天のマイページが死ぬほど親切に感じるほどに....。まあ 使い慣れるとAmazonの方がクリック数や入力工数が少なくていいんだけどね。
閑話休題。
この本の良いところを。
仮想マシンだから何でもできます〜じゃなくて、典型的なサービス運用時の サーバートポロジーの説明が図入りである(笑) こと。 バックアップ構成についてしつこく解説してあること。ここらへんは実際にEC2使って 企業向けSaaSを提供している筆者ならではなんだろう。
細かいところだと「カスタムAMIはロケーション超えて起動できない」とか 「smallとlargeでは32bit/64bitで仮想OSのカーネルから違う(から別々にカスタムしなくちゃならない)」とか「Apacheでは圧縮(mod_deflate)必須」とか書いてあるのが大変うれしかった。 「そんなの大規模サーバ運用ではあたりまえじゃん」 ...ハイごもっとも。 でもそれはIT方面専業でバリバリやってて経験値溜まってる人の発言ね。 俺みたいなエンベデッド技術者としては、なかなか目鱗なのよこれが!
しかし6,7章の「使い方」の部分は要らないと思う。ここはコマンドラインツールの 使い方や証明書の取得というところ。平易だがオンラインマニュアル含めてどこでも入手できる情報だ。 この本の良いところはほぼ5章より前にあるね。
全体的に一度読んだらOK、読み返す類の本じゃないけど..... サーバとかに興味ある人は読んでおくべきと言える。IT業界人より実は一般人向けやな、という感想。
2010-03-13 桃屋のラー油 [長年日記]
_ [雑記] 桃屋のラー油
辛そうで辛くない少し辛いラー油 マジでどこにも売ってないなあ。少し前までは近所のスーパーに 余りまくっていたのだが...
_ [雑記] ラー油を作る
なければ作ればいいじゃない とかいう声が聞こえてきたので、 適当にチャレンジしてみる。
まずにんにく1個とタマネギ1/2個でフライドオニオンとガーリックを作る。揚げすぎないように注意。色づく前に止めておく。

|
スパイスは、赤とうがらし、干しエビ、豆、ローズマリー、クローブ、しょうが、黒こしょう適量。
フライドオニオンを引き揚げたら油を捨て、新しくサラダ油(できればごま油)をひいて180度くらいに暖める。これをスパイスの鍋に注ぐ。直接火にかけないのは香りを飛ばさないためです。
冷めたら油を漉して瓶に詰め、ごま油大1と砂糖小さじ1と甜麺醤小さじ1を加えてよく混ぜる。こう見ると厳密には「ラー油」ではないなこれ....
んー...香りは抜群に良いものの「うまみ」が絶対的に足りない。本物には化学調味料が沢山はいっていそうだ...
2010-03-14 ビーッビーッ [長年日記]
_ [雑記] UPSが壊れた
4時40分くらい突然居間からアラーム音が....
そりゃ起きましたとも....
電池が壊れたらしい。
![]() OMRON BP50XF 交換用バッテリパック(BX35XFV/BX50XFV用
OMRON BP50XF 交換用バッテリパック(BX35XFV/BX50XFV用
8000円の電池...高いな... アマゾンだと本体高いんだけど、 NTT-X Storeだと 本体1万円なんだよね(当然電池付き)。本体分は差額2000円か...と考えてしまう。
本体といえば サウンドハウスのこれ怪しさ爆裂だけど OMRONの電池だけより安い!!大丈夫なのかこれは....
マジ悩むわ。
まあしばらくUPSナシなので、落ちたら俺がマンソンに帰るまでそのままです。よろしく。こういうときこそアフィリエ....いやなんでもないです(笑)
2010-03-15 Tokyo Cabinetで遊ぶ [長年日記]
_ [開発][Linux] 噂のTokyo Cabinet
mixiのアーキテクトである 平林幹雄さんの一連のソフト群は mikio ware と呼ばれ、筋(どの筋?)では有名です。 いろいろなものを作られているのですが、最近、富に注目を浴びているのは、 Tokyo Cabinet / Tokyo Tyrant と呼ばれる軽量データベース。

|
個人的にはSQLite3という、 組み込みリレーショナルデータベースを良く使っていたのだが、 いくつか問題にぶち当たっていて、これを解決する手段を探していたというわけ。
- 原則DBロックで2,3プロセスから書き込むと良く更新失敗する
- RDBMSなので割と真面目にテーブル設計しないといけない
- 登録が遅い!トランザクション使えば速いがそのロック期間は(1)の問題が生じる
- サーバ実装のデファクトがない
- レプリケーションがない
- パフォーマンスチューニングの余地が少ない
特に1番めの欠点を直そうとSQLite3を改造しようとして挫折した経験あり(笑) これができないとウチのような小規模Webページでも大変困ったことになるのです。
一方Tokyo Cabinetは、RDBMSではないのでテーブル同士のJOINなどはできないものの、
- mixiの更新時刻処理に使われていて毎秒数万アクセスをさばいている(らしい)
- ハッシュ、B+木、固定長、テーブルDBを選択でき、テーブルDBは非常に理解しやすい
- Tokyo Tyrantというサーバ実装がある
- レプリケーションがある
- ハッシュ表やリーフ(ノード)サイズが細かく制御でき、かつzlib/bzip2による圧縮もサポート
という素晴らしい特徴があります。なかなかいい感じではないですか。
_ [開発][Linux] テーブルデータベースの基本
TCの真骨頂は、カリカリにチューニングしたハッシュデータベース(PerlやRubyの連想配列のようなKey-Value-Storage)にあるらしいのですが、私はテーブルデータベースにしか興味がないのでこれを使ってみます。
テーブルデータベースは、名前の通り「表」です。

|
が、SQLのテーブルとはだいぶ異なります。なんとカラムは自由に増やせます。特定の行だけに カラム'type'があって、他の行にはない、なんて事も可能です。SQLだとALTERで増やして、 デフォルト値で埋めるなんて作業をしなければなりませんが....
どうもTTは基本的にハッシュデータベースであり、 primary keyだけは特別 扱い しているものの、残りのカラムはすべてセルデータに結合して記憶されているようですね。 セルに「7」という数値だけではなく「type:7」という形で記憶されるようです。 事前にテーブル設計をしなくても良いのはメリットである半面、「typ o 」みたいな 間違いをしてもTT側でチェックしてくれる訳ではないのでハマりそうですな(笑)
あと、これは面喰らったのですが、サーバ版のTokyoTyrantでは基本的に 1つの初期化スクリプト=1データベース=1テーブルのようです。1データベースに 複数のテーブルを格納することはできないようです。つまりTCPポートが別々に分かれた 複数のサーバを起動しておくという使い方になるようです(少なくとも標準では)。
起動にはttserverというサンプルファイルを/etc/init.dにpostepgみたいな テーブル名と同じファイル名にしてコピーして所定の変数を書き換えます。 以下の例はポート1993にpostepg.tctという名前のテーブルを作成する例です。
# configuration variables prog="ttservctl" cmd="ttserver" basedir="/mnt/windex/postepg" port="1993" pidfile="$basedir/pid" #logfile="$basedir/log" #ulogdir="$basedir/ulog" ulimsiz="256m" #sid=2 #mhost="" #mport="1993" #rtsfile="$basedir/rts" dbname="$basedir/postepg.tct#opts=l#apow=8#dfunit=2" maxcon="1024"
chmod a+x postepgして/etc/init.d/postepgで起動します。
_ [開発][Linux] TokyoTyrantへのアクセス
Perl,Rubyなどのバインディングが存在しますが、私はPerlを使いました。
use TokyoTyrant;
my $pe = TokyoTyrant::RDBTBL->new();
die "ERROR: unable to connect" if (!$pe->open('localhost', 1993));
if ($pe->rnum == 0) {
$pe->setindex($pec->{'eventid'}, $pe->ITDECIMAL);
$pe->setindex($pec->{'nibble'}, $pe->ITTOKEN);
$pe->setindex($pec->{'provider'}, $pe->ITLEXICAL);
$pe->setindex($pec->{'title'}, $pe->ITQGRAM);
}
$pe->close();
ちょっとハマったのは データベースのタイプを合わせること ですか。hogehoge .tct をデプロイしている サーバにアクセスするためには、必ずTokyoTyrant::RDBTBLを使わねばなりません。 まあ少し考えればわかることですが...
登録数が0のときにインデックスを張っています。数値はITDECIMAL、文字列辞書式順はITLEXICAL、 「ニュース,報道」みたいなカンマや空白で区切られた複数の意味を持つ文字列はITTOKEN、 自由な単語で検索したい文字列にはITQGRAMを付与します。これで検索などが高速化されます。
データの登録はprimary keyを取得して、それに対してPerlのハッシュリファレンスをputします。
my $cols = {
'eventid'=>23435,
'nibble'=>'2f 情報・ワイドショー その他',
'provider'=>'NHK総合',
'title'=>'おはよう日本'
};
my $rkey = $pe->genuid();
$pe->put($rkey, $cols);
検索結果はprimary keyのリストで返ってくるので、それを使ってgetします。 Q-GRAMのインデックスを張っておくと、SQLite3のlikeなんて目じゃない柔軟な検索が可能になります。 ちなみにQCFTSANDは空白で区切られた単語単位のAND検索。Googleとまではいかないけど、 こんなお手軽に柔軟な検索ができるようになるのはTTのメリットでしょう。
my $qry = TokyoTyrant::RDBQRY->new($pe);
$qry->addcond('title', $qry->QCFTSAND, 'よう 本');
my @rlist = $qry->search();
foreach my $rkey (@rlist) {
my $rcols = $pe->get($rkey);
print $rcols->{'title'} . "\n";
}
基本はこれだけ。
_ [開発][Linux] ベンチマーク
ベンチマーク用にtcttestというコマンドが用意されているので、どのくらい速いか調べてみた。 インデックスは張りまくりの条件です。
tcttest write -tl -ip -is -in -it -if -ix ./test/test.tct

|
Q-GRAM転置インデックス生成を含む6種類のインデックスを張りながらでも、 250万レコード平均で4800レコード/秒というすさまじい速度です。 100万レコードから250万まで測定しましたが、微妙に時間が延びるもののほぼ線形。 ディスクの延びもほぼ線形でした。
最近はスケールアウトが流行りですが、これだけ速ければTC一つで事足りる事例も 多いのではないでしょうか。特に個人では.....
次は検索時間を調べてみたいと思います。
2010-03-16 SheevaPlug来た [長年日記]
_ [開発][Linux] SheevaPlugが届いた
New IT UKに注文していたSheevaPlug開発キットが届いた。 Paypal経由で3月5日に注文して3月13日には地元の郵便局まで届いていたのだが、 俺がポストに投函された不在届けを全く見ず放置 されていたのだ(^_^;;;ヒドス....

|
お値段送料込みで146GBP、およそ19918円。日本で販売されている 玄柴と比較すると 遥かに高いですが....
__ __ _ _
| \/ | __ _ _ ____ _____| | |
| |\/| |/ _` | '__\ \ / / _ \ | |
| | | | (_| | | \ V / __/ | |
|_| |_|\__,_|_| \_/ \___|_|_|
_ _ ____ _
| | | | | __ ) ___ ___ | |_
| | | |___| _ \ / _ \ / _ \| __|
| |_| |___| |_) | (_) | (_) | |_
\___/ |____/ \___/ \___/ \__|
** MARVELL BOARD: SHEEVA PLUG LE
U-Boot 1.1.4 (Jul 14 2009 - 06:46:57) Marvell version: 3.4.16
U-Boot code: 00600000 -> 0067FFF0 BSS: -> 006CF120
(省略)
## Booting image at 00800000 ...
Image Name: Linux-2.6.32.7
Created: 2010-02-10 21:21:03 UTC
Image Type: ARM Linux Kernel Image (uncompressed)
Data Size: 2822164 Bytes = 2.7 MB
Load Address: 00008000
Entry Point: 00008000
Verifying Checksum ... OK
OK
Starting kernel ...
(省略)
Debian GNU/Linux squeeze/sid debian ttyS0
debian login:
(ブートログはこちら)
そう!! newIT UKのeSata Sheeva MultiはDebian6.0を選べる のだ!! Debian入りのSDHCカードからブートするようにu-bootも設定済み。とっても楽ちんです。 「イメージの作成くらい自分でやれよ...」という話もあるが、ちょっと遊ぶだけだからこれはうれしい。
でも何に使うかは決めてない....(´ー`)
2010-03-17 SheevaPlugで遊ぶ(2) [長年日記]
_ [開発][Linux] 特に進展はないです
NewIT UKのDebianイメージを4GBのminiSDカードにコピーしてコンパイル 環境を構築して、いろいろ試している。速度はAtom230(シングルコア)の1/2〜1/3くらいかなあ。1.2GHz!!ちう感覚でパソコン並みのことをやらせるのは、ちょーっと無理がある速度かな。
尚、玄柴と違ってNewIT UKのUS Plug KitはAC変換コネクタがついているため、こんな設置が可能。

|
ある意味PlugComputingのコンセプトを体現できたようなキモス。 ちょっと大きめのACアダプターなのに、 中身はARM9相当1.2GHzのCPUとメモリ512MBを搭載したLinuxサーバ なわけだから。ああ、遅いと言っても玄箱HGやらPROやら白箱やらとは 比較にならないほど速いです。クロック高いのもあるけど、 多分アウトオブオーダーがけっこう効いてる予感。
でもこのMarvellのCPU、ちょっと謎。cpuinfoだとARMv5TEとして 認識されてはいるものの、 mplayerなどで--enable-armv5teするとアセンブラレベルで 除算命令ないとか言われて コンパイルが通らない(ARM9Eベース?)。 ARMは派生命令セットが多くてわからない.....
マルチメディア系のオープンソースは BeagleBoardなどに搭載されてる Cortex系SOCに合わせて作られてる予感がするなあ....MarvellはNAS専用?
2010-03-18 SheevaPlugで遊ぶ(3) [長年日記]
_ [開発][Linux] u-bootの設定について
玄柴と比較して、このeSATA SheevaPlug Multiというのは u-bootの設定がかなり異なるようだ....。
Hit any key to stop autoboot: (起動時リターン連打でu-bootプロンプトへ) Marvell>> printenv [ENTER] bootcmd=run bootcmd_mmc; run bootcmd_nand bootcmd_mmc=setenv bootargs $(bootargs_console) (*実際は1行) $(bootargs_root_mmc); mmcinit; (*実際は1行) ext2load mmc 0:1 0x800000 /uImage; bootm 0x00800000 (*ここまで) bootcmd_nand=setenv bootargs $(bootargs_console) (*実際は1行) $(mtdpartitions) $(bootargs_root_nand); nand read.e (*実際は1行) 0x00800000 0x00100000 0x00400000; bootm 0x00800000 (*ここまで)
なるほど、先に外付けSDカード(Debian)をブートしようとして、 失敗したら内蔵NAND(Ubuntu)を起動するようになっているわけだ。便利だな..... 使っているその他のパラメータはこんな感じ。
bootargs_root_mmc=root=/dev/mmcblk0p2 rootdelay=5 bootargs_root_nand=ubi.mtd=1 root=ubi0:rootfs rootfstype=ubifs mtdpartitions=mtdparts=orion_nand:0x400000@0x100000(uImage),(*実際は1行) 0x1fb00000@0x500000(rootfs) (*ここまで) bootargs_console=console=ttyS0,115200
bootargs_root_mmcのrootパーティションが/dev/mmcblk0p2なので、 おそらく2番めのパーティションがrootなのだろう。
_ [開発][Linux] 内蔵NANDとUBIFS
内蔵NANDもカスタムカーネルが採用されており、rootfsはjffs2よりも高速なUBIFSが 採用されているようだ。ハードウェアは同じだけど、そこかしこに手が入ってるのね。
Uncompressing Linux........ Linux version 2.6.32.7 (newit@gemini) (gcc version 4.4.1 (Sourcery G++ Lite 2009q3-68) ) #5 PREEMPT Wed Feb 10 21:09:39 GMT 2010
これ幸いとばかりにNANDでUbuntuブートしてから、SDカードのDebianを母艦(192.168.11.2)に バックアップ。書き戻すときはtar xvpfね、念のため。
# mkdir /mnt/test1 # mount /dev/mmcblk0p1 /mnt/test1 # cd /mnt/test1 # tar cvf '-' . | ssh papanda@192.168.11.2 "cat '-' > /tmp/debian_kern.tar" # cd .. # umount /mnt/test1 # mount /dev/mmcblk0p2 /mnt/test1 # cd /mnt/test1 # tar cvf '-' . | ssh papanda@192.168.11.2 "cat '-' > /tmp/debian_root.tar" # umount /mnt/test1 # cd ..
見た感じSDカードのフォーマットは単純そのもの。Linuxパーティション1にuImageというファイルが1個、 Linuxパーティション2にrootfsをそのまま置けば良さそうだ。NANDと違ってすごい簡単ね。
試しにNewITの添付のSDカードとは容量の異なる、2GBのSDカードに、 似たようなパーティション切って、上のアーカイブを展開したけど、 全く問題なく起動したよ(実環境はこのカードで構築中)。
ここまでLinuxの基礎的な知識を動員している以外、SheevaPlug関連の 情報はほとんど使ってない(笑)マジ適当にやってマス。 それもこれも、 NewIT UKが最初から設定を済ませてくれている からだね.....。 これをポチったときは「やっちゃった」感ありありだったわけだが (ポンド/円の為替レートに無頓着だったというのもある...)今では玄柴買わなくて良かったと思ってる!
2010-03-19 Linuxで激安B-CASカードリーダー [長年日記]
_ [PC][Linux] B-CASカードリーダー

|
秋葉原の三月兎などで1000円以下で売っているTFTEC SCR001 という激安カードリーダー。 Windowsドライバではスタンバイ復帰などに問題があるらしいが...

|
Linuxで特に問題なく使えました(スタンバイは試してないよ、サーバだし)。 設定は SCR3310-NTTComの時と同じ です。いやそれだけ。
2010-03-23 Tokyo Cabinet/Tyrantで遊ぶ(2) [長年日記]
_ [開発][Linux] Tokyo Cabinet/Tyrantで遊ぶ(2)
テーブル型のストレージをサポートし、制限はあるもののRDBMSと似たような感じに使える(はず)の Tokyo Cabinet。 実際にデータを登録して性能を見てみました。
まず生成条件。64bit有効でアライメント力256バイト(2^8)。CabinetではなくTyrantで接続。
dbname="$basedir/chest.tct#opts=l#apow=8#dfunit=2"
1行当たりのデータは....ちょっと仕事のデータを使ってしまったので(ぉ) 具体的には説明できないのですが、整数型x8,文字列型x3です。文字列型(UTF-8)で 1行当たりの平均バイト700バイト程度、最大2.1KBです(*けっこう大きい)。 また、整数カラム5つの完全一致でUNIQUEな制約がついています。SQL風に書くと(仮)、
UNIQUE(emptype, bumonid, groupid, nyuusyanendo, zyugyoincode);
みたいな感じです。上記の条件が全部一致した行は重複して登録したくない、ということです。 このデータを571265行登録してみました。
登録条件は以下の通り。
- noidx: インデックスなし, 重複チェックなし
- idx: 整数型7種類にDECIMALインデックス,文字列型にQ-GRAMインデックス,重複チェックなし
- search: 上記のインデックスを生成しながらUNIQUE制約を1行毎にRDBQRYを発行することで実行
結果は以下の通り。横軸は1万行ごと、縦軸は1秒当たりの処理行数です。

|
既存テーブルを検索してみて無かったら新規登録する という処理は非常にありがちだと 思うのですが、ちょっと実用にならないくらい遅い....あまりの遅さに断念しました。
_ [開発][Linux] いやいやKVSなんだからprimary keyを工夫しなくちゃダメでしょ
そうでした。KVSは基本ハッシュデータベースなので、主キーの取り方で制約を実現できるのです。 つまり、ユニークIDをもらってくるこういう関数よりも、
my $id = $jinji->genuid();
どうせ文字列も使えるのだからキーをsprintfか何かで生成してしまえばよいのだと。
my $id = sprintf("%d_%d_%d_%d_%d", $emptype, $bumonid,
$groupid, $nyuusyanendo, $zyugyoincode);
これなら被ることはないし、被った場合は後から来たデータで上書きされるだけ。 もちろん「登録しない」ということと「上書き」は全く異なる処理だけど、 今回の用途では問題ないのでやってみた。

|
通常の連想配列の実装では、ハッシュ関数を通すオーバーヘッドはあるはずだが、 キーの長さはほぼ一定なのだから処理時間も一定のはず、なんだけどなー。 これもあまりに遅いので打ち切った。
_ [開発][Linux] 「上書き」がいけないのかな....
後から来たデータで更新するのを抑止するにはputkeep()関数を使えばよいようです (ニューレコードのみ登録する)。 現実には上記のテストデータは全てユニークだから、UNIQUE制約にひっかかることはないので、 put()関数と違いはないと思っていたのですが....

|
やっぱり変わりません。 次いこ次。
_ [開発][Linux] 衝突が起きまくっている?
という推測も成り立つ。テーブルデータベースは、 ハッシュテーブルの各要素にBtreeのポインタが入ってる....という実装なのかなあ。 ってことは、ハッシュテーブルが疎になるような設定をしなければならないんだろう。 ざっと基本仕様書読んでbnumは関係ないと勝手に思い込んでいた。 57万件ということは2倍の100万件くらいにしておけばいいかな。
dbname="$basedir/chest.tct#opts=l#bnum=1000000#apow=8#dfunit=2"

|
やっぱり変わりません。 万策尽きてきた.....
_ [開発][Linux] 諦めて基本仕様書を読み直す
基本に立ち戻ってつらつらと.....
bool tctdbsetindex(TCTDB *tdb, const char *name, int type);
`tdb' specifies the table database object connected as a writer.
`name' specifies the name of a column.
If the name of an existing index is specified,
the index is rebuilt.
An empty string means the primary key.
え? An empty string means the primary key. ?? ということはデフォルトでは主キーにもインデックス貼られてないの??? そんなバカな....
$jinji->setindex('', $pm->ITLEXICAL);
を追加。

|
俺にはTokyo Cabinetは使いこなせないようです。
_ [開発][Linux] わかった!!!!!
いままでやってたの全部的外れ!!!!
お気軽全文検索 をやりたかったので安易にQ-GRAMインデックスを張っていたのだが.....仇になった。
以下のサンプルで再現できる。
- Debianでttserverを起動
- /tmpにoriginal.txtを置く
- perlでtyrant.plを起動
tyrant.plはttserverへ接続してテーブルを登録する。キーは数値。 重複チェックはttserverでおまかせ。1行登録するたびに、 original.txtから1行読んで全文検索のインデックスを貼る、というのが サンプルのアルゴリズム。
しかし、このoriginal.txtが添付の数行みたいなものであれば問題ないのだが.... 多彩な文字の組み合わせを含むソースだとバカみたいに素片量が増えてしまい、 登録時間もうなぎ登りになってしまうようだ。手元では2ちゃんねるのdatログを 数十個結合したもの差し替えてみた。つまりヘッダありAAありというテキスト行が3万行 くらい続いているわけ。これで全文検索のインデックスを作成すると、 毎回確実に適当な単語が追加されていく。
グラフの横軸は1万件ごと、縦軸は1万件を登録するのにかかった秒数。
ファイルサイズを見てみよう。
-rw-r--r-- 1 root root 125237504 2010-03-23 19:18 testdb.tct -rw-r--r-- 1 root root 111360 2010-03-23 19:06 testdb.tct.idx.10.dec -rw-r--r-- 1 root root 23888640 2010-03-23 19:18 testdb.tct.idx.11.dec -rw-r--r-- 1 root root 111360 2010-03-23 19:06 testdb.tct.idx.2.dec -rw-r--r-- 1 root root 14170624 2010-03-23 19:18 testdb.tct.idx.3.dec -rw-r--r-- 1 root root 534364416 2010-03-23 19:18 testdb.tct.idx.6.qgr ※これ!! -rw-r--r-- 1 root root 111360 2010-03-23 19:06 testdb.tct.idx.7.dec -rw-r--r-- 1 root root 111360 2010-03-23 19:06 testdb.tct.idx.8.dec -rw-r--r-- 1 root root 111360 2010-03-23 19:06 testdb.tct.idx.9.dec
これはひどい......... 本文が格納されているであろうtestdb.tctよりはるかにデカイ... 登録時間を一定にするのは難しいんだろうか??できれば単語の種類の量じゃなくて、 毎回登録する1行のテキストの長さだけに処理量が比例して欲しいんだけど.... でも俺が同じもの作ったらさらに1/100くらい遅いだろうしなあウムム.....
まあ、適材適所というか、Q-GRAMは使わないほうがいいですね。
2010-03-24 Tokyo Cabinet / Tyrantで遊ぶ(3) [長年日記]
_ [開発][Linux] Tokyo Cabinet / Tyrantで遊ぶ(3)
一番気になっているのは、Q-GRAM転置インデックスを作成するだけで、登録時間がわずかではあるが級数的に伸びていること。これがlogみたいなグラフを描くのなら安心して使えるのだが 2000万件超えた当たりで1登録あたり257時間かかりますね(^^; とか言われるとマジ死ぬ。
わかったことをいくつか。インデックス生成含め検索操作の関数群はtctdb.cにほぼ全てまとまっている。 そこでtctdbsetindeximpl関数をみると
case TDBITQGRAM:
idx->db = tcbdbnew();
idx->cc = tcmapnew2(TDBIDXICCBNUM);
idx->name = tcstrdup(name);
tcxstrprintf(pbuf, "%cqgr", MYEXTCHR);
if(dbgfd >= 0) tcbdbsetdbgfd(idx->db, dbgfd);
if(tdb->mmtx) tcbdbsetmutex(idx->db);
if(enc && dec) tcbdbsetcodecfunc(idx->db, enc, encop, dec, decop);
tcbdbtune(idx->db, TDBIDXLMEMB, TDBIDXNMEMB, bbnum, -1, -1, bopts);
てなわけでB+木データベースそのものらしい。実際に出来上がった*.qgrファイルをhoge.tcbという ファイル名にリネームしてtcbmgrでダンプしてみる。
$ tcbmgr inform hoge.tcb path: hoge.tcb database type: btree additional flags: comparison function: lexical max leaf member: 64 max node member: 256 leaf number: 34150 node number: 191 bucket number: 9209 alignment: 256 free block pool: 1024 inode number: 1171692 modified time: 2010-03-24T10:44:13+09:00 options: large record number: 594699 file size: 305556224
あー....20万行しか登録してないのに59万個の単語にわかれているのか。 そりゃ遅いかもな。でも、BTreeの素直な実装だと検索時間はO(log n)に依存し、登録操作もほぼ同様なはず(どくらいの単位でひとまとめにしてるかに依存するが)。 でもこれって、6万行を超えたあたりから急速に処理時間が延びる説明にはならないんだよね。
まあdcbdbtuneを読んでいる箇所はわかったので、 基本仕様書のB木チューニングの章を 読んでチューニングしてみたが、これまた芳しくない。一応、
tcbdbtune(idx->db, 24, TDBIDXNMEMB, bbnum, 12, -1, bopts)
が一番速いようだがせいぜい数%.....ボトルネックは別にあるのかな。
リーフ内メンバ数やバケット数をいじっても、ほとんど変わらないかむしろ悪化する場合が大半だった。
- TDBIDXLMENBを24に変更
- bbnumを20000000変更
- TDBIDXQGUNITを3から4に
- TDBFTSBMNUMを524287から687903に変更
- tcbdbsetxmsiz(idx->db, 1024*1024*1024);
などなど。
_ [開発][Linux] gprofの結果
TC/TTのconfigureはプロファイル出力をサポートしており
$ ./configure --enable-profile
でコンパイルしなおすとgmon.outを作ってくれる。これでインデックスありとなしを比べれば 特徴的な処理が洗い出せる....はずだと思ったんだけど。
インデックス一切無しの場合:
Q-GRAMインデックス有りの場合:
正直パーセンテージだけ見ると違いがわからん。Q-GRAMの時だけ、特定関数がものすごい勢いで 呼ばれてるとか、とても時間を食う関数が呼ばれているとか、そういう単純な問題ではないようだ。 総合的なI/Oスループットの問題だとすると、チューニングは実に厄介だ。
_ [開発][Linux] 抜き身のナイフ
読んでみてなんとなくわかったのは設計思想で、 Tokyo Cabinetはいわゆる安全側に振ってあるRDBMSとは全く違う。抜き身のナイフのようなもの。 俺みたいな素人がお気軽に手を出せるモンじゃねーな.....
例えば。tcmapput関数などを生でmmapしたファイルにガンガンポインタベースでmemcpyしちゃう。 「え?普通じゃん?」と思うかもしれないけど、RDBMSではまずやらない。 書き込めない場合の回避処理が大変だからね。
実際、昨日のサンプルを、少量のtmpfsを切った上で実行したら ttserverがバスエラーで落ちてワロタ 。バグじゃなく仕様なんだろうなあ、これ。
ああ、TCのネガティブキャンペーンをしている訳ではありませんので。念のため....。
2010-03-25 Tokyo Cabinet / Tyrantで遊ぶ(4) [長年日記]
_ [開発][Linux] Tokyo Cabinet / Tyrantで遊ぶ(4)
TC/TTの勉強がてら、2chの過去ログ検索システム(1投稿毎)を作るつもりだったのに、 なんかメチャクチャハマっとるぱぱんだです。こんにちは。
とにかく Q-GRAMの登録処理が遅い というのが前回までのあらすじ。 現象面からの洞察や、仕様書に書いてある最適化はやり尽くした感があるので、 もうソースを読むしかない。
_ [開発][Linux] モコモコ穴堀り
手打ちプロファイルにより、*.qgrファイルを更新する関数を調べる。 tctdbput()->tctdbidxputqgram()->tctdbidxsyncicc()と処理を追っていと...
tctdbidxsyncicc()関数内の
for(int i = 0; i < knum; i++){
...
const char *vbuf = tcmapget(cc, kbuf, ksiz, &vsiz); //*T1
if(vsiz > 0 && !tcbdbputcat(db, kbuf, ksiz, vbuf, vsiz)) //*T2
tcmapout(cc, kbuf, ksiz); //*T3
}
で時間の大半を消費していた。どうもQ-GRAMインデックス(を格納するB+木)を ディスクにフラッシュする部分のようだ。上記の関数のそれぞれの実行時間の合計を 洗い出すと、特にtcbdbputcat()の処理時間が多い。手持ちの2chのdatだと 18万件登録する頃には、もう 1投稿処理するのに1秒超えてしまう ....使い物にならない。
DELAY: tctdbput() = 1 . 178601
t1 = 0 . 10234
t2 = 1 . 137749
t3 = 0 . 13995
t4 = 0 . 0
でも、これが全キーワードの追加時に1秒超えるのではなくて、極々 特定のキーワードのみ のようなんですよ...... なんかピンときた ので、 スクリプトdumpbtree.plを作った。 これはB+木の、各キーワードと、キーワードごとの値の長さ (この場合は転置インデックスのバイナリが入っているのでバイト長)をダンプする。出力を
$ perl dumpbtree.pl test.tct.idx.6.qgr > qgram1 $ sort -n < qgram1 > qgram2 $ tail qgram2
とかするとバイト長のランキングがとれるわけだ。
304128 います 390504 た。 398256 した。 432816 ました 437760 です。 443232 ます。 758688 す。 2399688 。
えー?!句読点や記号を 正規化の段階で省かない のか....んーmikio wareがそんな基本を 忘れるはずがないので、たぶん検索精度か何かの問題でわざと入れてるだろう。
B+木はキーでサーチしたリーフにどんどん値をコンバインできるのだが、 いくらなんでもこれが入ったらまずかろう。今までのリーフ内メンバ数の調整なんて、こいつがメモリキャッシュに入ってきたら全部オジャンじゃん.....しかも書き足したら書き出す必要がある=ディスクにアクセスする、という悪循環。
尚、「。」を含めた上位100傑を取り除いた全体の分布はこうなる。 横軸が単語ごと、縦軸がバイト長(ソート済み)ね。壮絶に偏るなあ...
別に2ちゃんねるの文章が飛び抜けて特殊なわけではなく、対象文章がちょっと多ければ、いずれ同じ問題にブチ当たると思う。つまり現状のTCのQ-GRAMは、本当に個人ブログの文章のみなど、文字の組み合わせが少ない場合にしか使えないということだね。
まあ、たぶん.....掲示板などの文字の組み合わせが膨大になる場合は Tokyo Distopiaつかえってことだな。 でもこれ、ツンツン過ぎて俺のような素人には辛いぞ!
2010-03-26 もうCPAN手打ちには飽きたお.... [長年日記]
_ [開発][Linux] Perlモジュールを簡単にDebianパッケージにする
つらつら勉強中。
 Perl Hacks ―プロが教えるテクニック & ツール101選(chromatic/Damian Conway/Curtis "Ovid" Poe/株式会社ロングテール/長尾 高弘)
Perl Hacks ―プロが教えるテクニック & ツール101選(chromatic/Damian Conway/Curtis "Ovid" Poe/株式会社ロングテール/長尾 高弘)
|
今までいちいち新しいマシンをインスコするたびに、
# perl -MCPAN -e shell
などとやってプロキシなどをconfigurationして数十コあるモジュールを 手動でインストールしていたのだが.... さすがに飽きた! なので調べてみたら、Debian GNU/Linuxには dh-make-perlなんて便利なコマンド があるらしいじゃないですか。
# apt-get install dh-make-perl
例えばmecab-perl-0.98.tar.gzのパッケージを作りたい場合は、 先に展開しておいてから、ソースディレクトリと説明を指定...と。
# tar xvzf mecab-perl-0.98.tar.gz # dh-make-perl ./mecab-perl-0.98 --build \ --desc 'Perl Module for MeCab(Japanese morphological analyzer)' # ls -l libmecab* libmecab-perl_0-mecab-config-1_i386.deb
ものの数十秒でdebができた はやすぎだろ!!
さらに読み進めるとCPANにあるパッケージはモジュール名さえ指定すればいいらしい。
# dh-make-perl --cpan CGI::FastTemplate --build
今までの苦労はなんだったの....これは便利過ぎる。
ところでRubyで同じようなのないですかね?
2010-03-27 はー重かった.... [長年日記]
_ [雑記][開発] さてここで問題です....

|
最近のCPUやSSDはパッケージが小さくて楽だね。 でも、電源3つはちょっと重かったかな。一人で黙々と買いあさっていたけど、マザーボードはもう持てないので1枚で断念。明日また行って2枚買わないと。
両手両肩に袋4つ抱えて思ったのは 高くても車にすればよかった... せめて友達呼べばよかった... 今襲われたら死あるのみ... の3点でした。
歩いたついでに、パーツ街に近い駐車場の値段を確認していたけど30分/400円とかで吹いた。1時間800円は足下見過ぎだろJK....最近はUDXの駐車場に入れるのが流行なんですかね。でも、後から荷物を置きに戻れないしなあ。青空駐車場がいいんだけどなあ。誰か穴場教えてください。あと8時間以内に!!
2010-03-29 重過ぎて手首おかしくなった [長年日記]
_ [開発][PC] ぱぱ式1Uサーバーを自作して失敗した
ずばり1Uラックマウント可能なサーバを自作する marqs blogの真似です。

|
 [24時間365日] サーバ/インフラを支える技術 ‾スケーラビリティ、ハイパフォーマンス、省力運用 (WEB+DB PRESS plusシリーズ)(安井 真伸/横川 和哉/ひろせ まさあき/伊藤 直也/田中 慎司/勝見 祐己)
[24時間365日] サーバ/インフラを支える技術 ‾スケーラビリティ、ハイパフォーマンス、省力運用 (WEB+DB PRESS plusシリーズ)(安井 真伸/横川 和哉/ひろせ まさあき/伊藤 直也/田中 慎司/勝見 祐己)
|
上記の本を読めば自動的に「サーバーリモート管理と言えばIntelのAMT!AMT!」...とIntelプラットホームに決まるはずなのだが
になってしまうのが俺の駄目なところだ。
_ [開発][PC] なぜAMDか
- はてなはCore2Quadかー
- うっわ!高い!全然値段下がってないのか!
- でもCore i5-750って先端プロセスなのにC2Qより安い!
- え?P55マザーでMicroATXでビデオ付きってないのか?!
- H55/57系のマザーは軒並みデュアル+HTTという糞石しか乗らない
- AthlonII X4 620とか9000円切ってるのに!ふざけるな!
- XEONでHTTは懲りたから信用しない、ネイティブクワッドで!
というわけで土日をフルに使って秋葉原中をかけ巡って、ハンドキャリーでサーバー3台分のパーツをかき集めていたという寸法ですわ。1UなのでP55/H55にビデオカードが差せないというところが全ての問題の発端なのだけど。マジでCPUにGPUニコイチ統合とか誰得だよなあ。面倒くさい。
_ [開発][PC] でも失敗の連続
はてなのよう百台単位で作るなら板金屋さんに頼んでもペイするのかもしれない....けど、数台では全く無駄。セルスペーサーの圧入?(PCケースのマザボをネジ止めする飛び出した部分、と言えば伝わるかな)だけはやりたかったが....まあIDCに置くわけじゃないし、両面テープと瞬間接着剤(笑)でなんとかなるかな〜と思ってこれにした。 MIDDLE ATLANTIC U1。 なんと2000円 ちう激安価格。一応、リアには金属の折り返しが付いていて3,4Kgくらいの部品ならたわまずに載せられそうだ。
マザボはそのまま載せるとDIP部品が接触して燃えるので、M4x5の溶接ナットを土台代わりに使うことにした。要するにこれをセルスペーサーの代わりにしたってわけ。

|
で、何が失敗したかってーと..... 高さ

|
サーバー向けでは全く必要のない7chオーディオ端子が邪魔をするんだぜ(笑)こんなこともあろうかと、マザーボードは3種類買ったのだが、
- GIGABYTE GA-MA785GPMT-UD2H
- MSI 785G-E65
- ASRock M3A785GMH/128M
DrMOSの低消費電力が魅力のMSIがまさかのヘディング(写真中段)。 いやなんでこいつだけオーディオ端子1mmほど高いの....他の2つは大丈夫なのに。

|
さらに電源も。はてな謹製サーバだと Enhance Flex300を使っているのだが(写真一番下)、 秋葉原中駆け回っても同一電源が九十九本店2Fに1台しかなかった。
ここの売り場の兄さんが親切な人で、在庫調べてもらったりしたんだけど。ワット数は少ないものの、 Seventeam ST-220FAB/24が使えそう という情報までいただいたので、これを買ったのね。 でも、Seventeamは微妙に大きく(写真上と中段)、粘着テープを貼ると40mmの高さ制限を超えてしまうのだ....なんて微妙な....。ケーブル取り回し含めて1Uに納めるのは想像以上に大変ということがわかった。
_ [開発][PC] さらにCPUも....
なんとか組み上ったものの、さらに1Uは無理あるなあと思ったのは当然 熱。 CPUは以下の3種類を買った。
- Phenom II X4 910e (2.6GHz,L2 512KB×4,L3 6MB, TDP 65W )
- Athlon II X4 605e (2.3GHz,L2 512KB×4, TDP 45W )
- Athlon II X4 620 (2.6GHz,L2 512KB×4, TDP 95W )
TDP(熱設計枠)を見れば、明らかに620が爆熱で苦労....と思われる でしょうが、実際にラックマウントして重ねてわかったのは Phenomの爆熱っぷり でした。なんていうんだろう、 もうとにかく熱い。CPUコア電圧を限界まで下げれば...と思ったら、 最初から1.15Vとかになってるし訳がわからん。BIOS読みでどんどん 温度があがって70度超えたので慌てて扇風機あてて電源切った。 マジ危ない。
AM2/3の1U低背クーラーで入手性が高いもの、というと、 Slim Silence AM2しか選択肢がない状況なので、 回避方法は 2Uあける 以外になかった.....どうしようもない。 この時点で1Uサーバの野望は潰えた。
一方で意外だったのは 95Wのはずの620の冷えっぷり デフォルトではそこそこ熱いんだけど、CPUコア電圧 超盛り(確か1.35V?)を止めて、1.175Vにしたら熱も出ないし クロックは高いし、かなり良い子でした。これ1万円切ってるのは マジお得だわ〜
もちろん605eが一番冷たい(もはや冷たい)んですけどね.... むしろ仕事しているのか怪しいほど冷たい。
_ [開発][PC] まさか作る奴はいないと思うけど
一応これならいけるだろうという部品表を置いておく。
- MIDDLE ATLANTIC U1
- 溶接ナットM4x4(3mmは接触危険、5mmは前述のように少し高い)
- M4x5ネジ
- アロンアルファゼリー状
- 3M超強力粘着テープ
- Athlon II X4 605e(無難)
- Slim Silence AM2
- ASRock M3A785GMH/128M(基板が最も小さいため,GIGAは最も大きい)
- DDR3 CFD Elixer 2GBx2枚
- Dirac DIR-2221-SRAIDE
- Intel X25-M Mainstream SATA SSD
- FLEX0130B-01XG
- 40x40x20mmの高速タイプのファン
- ATX12V延長ケーブル
- ATX電源24pin延長ケーブル(いずれも伸ばさないと届かない)
- L字型SATAケーブル(垂直だと干渉する)
だいたい7.5万円以下になるはず。
まあ、早くも後悔しているのはDirac DIR-2221-SRAIDEかな。AHCIで使えないらしいからTrimコマンドとかSSD関連の拡張コマンドは全部未対応なのか??せっかく正規代理店版X25-M買ったのに無駄なのだろうか(´・ω・`)
2010-03-31 やれやれ熱くなってきたぜ [長年日記]
_ [Linux] PhenomIIでCPU温度を測定する
サーバーでCPU温度がわからないのは問題なので、 lm-sensorsをインストールする。
# apt-get install lm-sensors
各種センサーを認識させるにはsensors-detect。YESを押しまくると lm-sensorsがサポートしているチップを検出してくれる。 最後に/etc/modulesに書き込んでもいいか?と聞いてくるが、 ここだけNOがデフォルトなのでYESを入力して、リブートすれば モジュールが組み込まれる。
# sensors-detect
Trying family `National Semiconductor'... No
Trying family `SMSC'... No
Trying family `VIA/Winbond/Fintek'... No
Trying family `ITE'... Yes
Found `ITE IT8716F Super IO Sensors' Success!
(address 0x228, driver `it87')
Probing for Super-I/O at 0x4e/0x4f
しかし.....今回買った3種類のGIGABYTE,MSI,ASRockのマザーボードで、 ITEが載っていたのはGIGABYTEだけ(^^; でした。 いや〜一番高いMSIにも載ってなかったのはちょっと想定外ですわ。 載っていた場合はsensorsコマンドでファンスピードまで採れるんですけどね...。
# sensors it8718-isa-0228 Adapter: ISA adapter in0: +1.09 V (min = +0.00 V, max = +4.08 V) in1: +1.60 V (min = +0.00 V, max = +4.08 V) in2: +3.26 V (min = +0.00 V, max = +4.08 V) in3: +2.98 V (min = +0.00 V, max = +4.08 V) in4: +3.02 V (min = +0.00 V, max = +4.08 V) in5: +3.26 V (min = +0.00 V, max = +4.08 V) in6: +4.08 V (min = +0.00 V, max = +4.08 V) ALARM in7: +2.14 V (min = +0.00 V, max = +4.08 V) in8: +3.06 V fan1: 2556 RPM (min = 10 RPM) fan2: 3629 RPM (min = 0 RPM) fan3: 0 RPM (min = 0 RPM) fan4: 6367 RPM (min = 0 RPM) temp1: +40.0°C (low = +127.0°C, high = +127.0°C) sensor = transistor temp2: +60.0°C (low = +127.0°C, high = +127.0°C) sensor = thermal diode temp3: +55.0°C (low = +127.0°C, high = +127.0°C) sensor = transistor
_ [Linux] k10tempをインストール
新秀の介の日記をみると、 AMD系列にはk8temp→k10tempというCPU温度を取得するモジュールの系譜があり、 k10tempをコンパイルしてインストールすればいいらしい。 http://khali.linux-fr.org/devel/misc/k10temp/からソースを落としてきてmake.... おっとっと新しいDebianには開発環境が入って無かった。
# apt-get install gcc-4.3 make linux-headers-2.6.26.2-amd64
おもむろにk10tempをmake。できあがったkoをインストール。
# make # make install (depmodで失敗した場合は手動でdepmod -a)
/etc/modulesにk10tempを追加するか、手動ならmodprobe k10tempでも インストールできると思います。
# modprobe k10temp # sensors k10temp-pci-00c3 Adapter: PCI adapter temp1: +54.5°C (high = +70.0°C, crit = +74.0°C)
ところが!これまた今回CPUをAthlon_II_X4_620, Athlon_II_X4_605e, Phenom_II_X4_910eを買ったのですが、よりによって GIGABYTEに載ってるPhenomIIしか正しい温度採れない(^^;;;; という事態に。
正確には605eは異常に低く(15度とか出てた)測定されるが、620は全く0度のまま 動かないという状態。なんでじゃー。
コアが違うからですかね。それともまたマザーの違い??
不確実な情報でブランド信仰みたいなことを言いたくないけど、 やっぱりGIGABYTEが一番無難みたいだなあと....。 MSI、端子の配置や電源部分のヒートシンクは良いのだが、 BIOSが一番プアという問題があるしな。 ASRockはコストダウンの影響がモロに出ててVGA端子に補強が全くなく グラグラしまくるので怖いし。
_ [Linux] muninによる測定
muninをインストール済みなら、リンクをはるだけでグラフにできます。
# ln -s /usr/share/munin/plugins/sensors_ /etc/munin/plugins/sensors_temp # /etc/init.d/munin-node restart
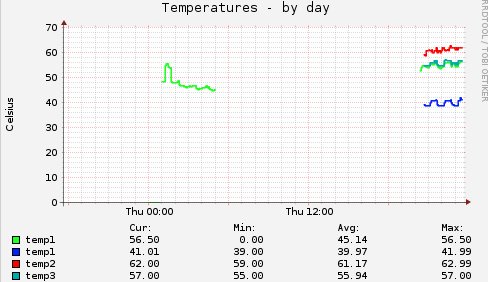
|
名前がtemp1でかぶっちゃってるけどk10tempの明るい緑のtemp1と、 ITセンサーからの暗めの緑のtemp3がほぼ同じということで、 多分CPU周辺の温度を測定しているのでしょう。 これで一応異常検出ができるかな....もっとも、 muninのグラフに現れた時点で完全死亡間違いなしだけどネ!
![[BANNER]](../image/banner.png)
このサーバーをもう12年も維持しているかと思うとめまいがしますよ。
ツッコミ機能は、ハンドル名が完全日本語じゃないと登録できません。
また、本文にURLが含まれていても登録できません。
いずれもSPAM対策です。
![[Panda Papanda]](../image/panda.jpg)
|
訪問者数:(11777+2560143)
- 2010-03-31
- PhenomIIでCPU温度を測定する
- k10tempをインストール
- muninによる測定
- 2010-03-29
- ぱぱ式1Uサーバーを自作して失敗した
- なぜAMDか
- でも失敗の連続
- さらにCPUも....
- まさか作る奴はいないと思うけど
- 2010-03-27
- さてここで問題です....
- 2010-03-26
- Perlモジュールを簡単にDebianパッケージにする
- 2010-03-25
- Tokyo Cabinet / Tyrantで遊ぶ(4)
- モコモコ穴堀り
- 2010-03-24
- Tokyo Cabinet / Tyrantで遊ぶ(3)
- gprofの結果
- 抜き身のナイフ
- 2010-03-23
- Tokyo Cabinet/Tyrantで遊ぶ(2)
- いやいやKVSなんだからprimary keyを工夫しなくちゃダメでしょ
- 「上書き」がいけないのかな....
- 衝突が起きまくっている?
- 諦めて基本仕様書を読み直す
- わかった!!!!!
- 2010-03-19
- B-CASカードリーダー
- 2010-03-18
- u-bootの設定について
- 内蔵NANDとUBIFS
- 2010-03-17
- 特に進展はないです
- 2010-03-16
- SheevaPlugが届いた
- 2010-03-15
- 噂のTokyo Cabinet
- テーブルデータベースの基本
- TokyoTyrantへのアクセス
- ベンチマーク
- 2010-03-14
- UPSが壊れた
- 2010-03-13
- 桃屋のラー油
- ラー油を作る
- 2010-03-01
- Amazon EC2/S3のすべて
_ 会長@腹部(tamoot) [見たこと無いですねぇ。。]
_ ぱ [gemの名前を指定するとdebかrpmができるとサイコーなんですけどねえ.....]