ぱぱネット(仮)
2013-10-28 古いCentOS5のyumが失敗する [長年日記]
_ [開発][Linux] 古いCentOS5のyumが失敗する
行きがかり上、自分が管理していなかったサーバを移管された。 これが今時 CentOS5 であり、そのまま捨ててやろうかと思ったけど、 DBの移行までやる気はナッシンなので、我慢してyum upgrade....
警告: rpmts_HdrFromFdno: ヘッダ V3 DSA signature: NOKEY, key ID 217521f6
うお?!リポジトリのキーが古すぎてアップデートできないようだ。サクッとアップデート。
# rpm -ivh http://dl.fedoraproject.org/pub/epel/5/x86_64/epel-release-5-4.noarch.rpm
同じエラーが出ている人は試してください。
_ [開発][Linux] VPS探し中
もうスポットインスタンスのAmazon EC2 t1.microで行くつもりだったのだが..... リモートバックアップなどをやらせようとすると 1晩たっても終わらず おかしいと 思ってネット速度測定したら、HTTPで80KB/sも出てなくてウケる。 確かに価格表みるとネットワークパフォーマンス:「非常に低い」なので、 こういう用途は使ってはいけない、ということなんだろう。
余談だが、AmazonはCPUもネットワークも上限抑え(シェーピング)が厳しい印象がある。 元々microは、他のインスタンスの隙間をぬって動くものだから仕方ないが。 後日ベンチマークをとってみよう。
まあ、個人的にはコストパフォーマンス最強のさくらインターネットで借りたいけど、 会社の名ばかりのIT統括部からは 「移管されたサーバはアメリカにあるので、アメリカのサーバにしろ」とのお達し。 EC2のlarge以上は高いしどうしたものか....
2013-10-22 AWSスポットインスタンスのすすめ [長年日記]
_ [開発][Linux] さくらのVPSが落ちていて仕事が滞った
コントロールパネルにつながらなくなって、 障害情報を見てみたら案の定であった。 さくらインターネットは、仮想サーバのコストパフォーマンスでは群を抜いているのだが、 コマンドラインツールがない上に 頻繁に前触れもなく落ちる のは、 仕事では割と勘弁してほしいところ。
必要なコストを支払わず、安く済まそうというのが悪いんだがな!
_ [開発][Linux] 少しでも安くEC2を借りる方法はないか
一方、AWSの方も長く使っているがほとんど障害の経験がない。枯れているっていうこともあるけど、サービス保証(SLA)にもいち早く対応し、返金もしてくれるってのはありがたい。でも....高いんだよねー....EC2。さくらのVPS2G = 1480円/月は、EC2のlarge〜extra largeくらいの性能なのだが、リザーブドインスタンスを活用しても13000円/月を下回ることは難しい。
少しでも安くEC2を借りる方法はないか? が今回の本題。
そこでEC2スポットインスタンスの出番となる。 本来は、ビックデータのバッチ処理や、巨大なシミュレーション計算など、落ちても良いが安くマシンパワーを借りたい用途で 使われるもの、らしい。オークション形式なので、予め設定した最大料金以下になると自動的にインスタンスを起動できる。 逆に言えば、Amazon側で立て込んで来たら、自分のインスタンスがバツンと落とされてしまうわけだ。
まあ怖い.... でも、今回は常設のサーバとして使うけど(笑)
値段を見てみると、オンデマンドの1/2〜1/5くらいで抜群に安いからね。リザーブドみたいに年間の初期費用も必要ないし、用途によってはコストパフォーマンス最強のさくらインターネットも下回るかもしれない、と思えるほど。
ちょっと比較してみよう(1時間当たり)。
| - | オンデマンド | スポット(最低) | スポット(95%) |
| t1.micro | $0.02 | $0.004 | $0.004 |
| m1.small | $0.06 | $0.01 | $0.03 |
| m3.xlarge | $0.5 | $0.092 | $0.092 |
| c1.medium | $0.24 | $0.028 | $0.1 |
常設サーバとして使うとすると、半日ぶっつづけで落ちてたりすると困るので、今回は1ヶ月くらいの推移をみて、95%くらいは起動してそうな料金を決めてみた(リージョンはus-west-2)。 値段をみるのは簡単で、AWS Consoleの「Spot Requests」⇒「Pricing History」から グラフが見られる。
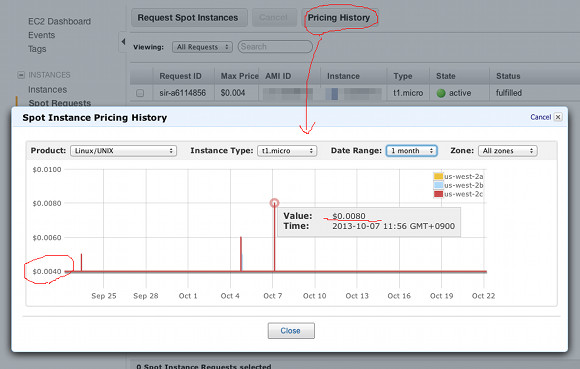
|
いろいろなインスタンス種別を見ていると「立て込み具合」がよくわかる。 隙間で実行されていると思われるマイクロインスタンスは殆ど変わらない反面、 medium以降はけっこう金額が上下していて設定に苦労しそうだ。
2013-10-08 Amazon Auto Scalingのパラメータについて考える [長年日記]
_ [開発][Linux] Amazon Auto Scalingのパラメータについて考える
Amazon EC2 + ELB + Auto Scalingは、動的サイトを自動的にスケールアウトするための、恐らく最も簡単で最もパワフルな解法だと思いますが、やっぱりそれなりの調整は必要です、という話をします。
世の中にあるCPU利用率によるアラームの例
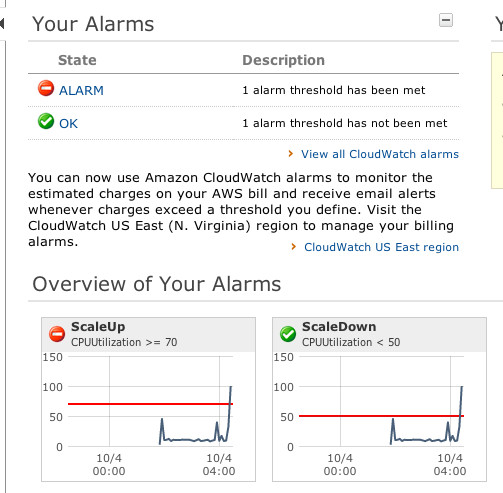
|
凡例としては一番簡単な設定ですが...実際にやると、どうにもうまくいかないんですよ。
|
- CloudWatch無料枠だとAlarmが5分間隔しかない
- EC2インスタンスが起動して利用可能になるまで時間がかかる
- そもそも「高負荷」の条件はCPU Boundなのか
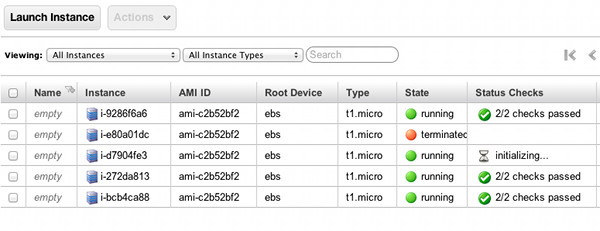
という3つの問題があります。つまり、急激にトラフィックが増減するアプリケーションにAmazon Auto Scalingはむいていないようです。 確かにベンチマークなどで負荷をかけるとインスタンスは順次起動されますが、Initializingの待ちが相当まだるっこしいですな。
|
【チューニング1】スペアサーバを沢山用意しておく
予め需要トラフィックが捌けるだけの台数を用意しておけば、 スケーリングする必要がありません。対策としては基本過ぎるのですが、 新規サービスで需要を予測するのはかなり難しいです。
【チューニング2】 増減するサーバ数を増やす
Alarm発報からインスタンスが起動するまで10分だとすると、10分間はサービスが怪しくても、10分後にはかっちりアクセスを捌けるようになりたいですね。なので、auto-scaling-policyのサーバ増加台数をチューニングすることが重要になってきます。もっとも、トラフィックが減ってもサーバ台数が減らないと課金で死ぬんで減少台数も見極めましょう。
【チューニング3】 高負荷条件を見直す
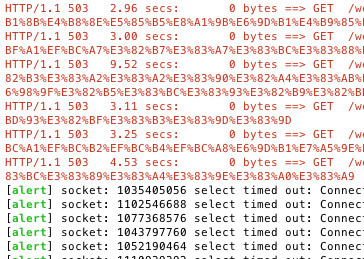
つまり 「いち早く兆しを掴んでAlarmを発報する」 今回言いたいのはコレ。。文章にすると当たり前ですが....条件は当然アプリによって異なるので難しいです。
私が今作っているサービスの場合、そこそこ重い処理をApp(Web)サーバでやっていて、負荷をかけるとCPUが上昇する前に、503 service unavailableを返すことがわかりましたので、これで条件設定をしています。

|
一つ前のプルダウンメニューで統計情報を「合計(sum)」に変更しています。(多分)5分間に補足された503エラーの合計...という意味になると思います。

|
今度はうまくいったようです。
|
2013-10-04 Amazon EC2 AutoScaling & Elastic Load Balancer cheat sheet. [長年日記]
_ [開発][Linux] Amazon EC2 AutoScaling & Elastic Load Balancer cheat sheet.
まえがき
オンプレミス(自社、自宅サーバ)の時代から、 公開Webサービスをやるものにとって、アクセス負荷分散は避けて通れないところです。 こういった負荷分散は、通常ロードバランサで行います。apache2でもnginxでも設定すればできますね。 さらに冗長化も考えるとVRRPを吐くKeepalivedあたりが定番でしょうか。poundなんかも設定が簡単で良いですね。
しかし、オンプレミスで Webサーバの方を負荷に応じて台数を増減するとなると相当敷居の高い 話になります。 サーバの台数をおいそれと増やす訳にはいかず、上限は決まっているわけですから。
でもクラウドなら、サーバの台数もスペックもある程度自由にできます。ポチッとすると5分くらいでサーバは用意されますよね。 いっそ アクセスに応じてサーバの台数を可変してくんないかなー と思いますね。 AWSでこれを実現する仕組みがEC2 AutoScaling & Elastic Load Balancerです。
......ここまでは前置きですが、ネットを調べた感じ、日本語で具体的な手順を記した資料があまりなく、 見つけた講演会かなんかのPPTに書いてあるコマンドラインを打ってもエラーが出てすごい苦労したので、 チートシートにまとめることにしました。
方針は「Web(AWS Console)でできることはそこでする」です(笑)
あと、これ動的サイトの話です。静的なHTMLと画像のみのサイトは、 こんな面倒なことをしなくてもS3とCloudFrontでできます。
AMIの作成
ここはさらっと。
* インスタンスをセーブしてAMIを作成しておく。 * ami-id(ami-XXXXXX、など)をひかえておく。 * ヘルスチェック(正常時必ず200,異常時5xxを返す)ファイルを用意してからセーブすること。 * 起動時にWebサーバが自動起動するようにしておくこと。 * AMIのリージョン(us-west-2、など)を確認しておく。
ELBの作成
ロードバランサー(ELB)の設定をしておく。
* Load Balancer Nameをつける(www2、など) * Create an internal load balancerのチェックをしない * Load blaancer Protocolはデフォルト(HTTP:80)のまま * Security GroupsはAMIのデフォルトで良いでしょう * Response Timeoutは、該当するCGIがかかる最大秒数を設定(60秒以上は工夫が必要) * Manually Add Instances to Load Balancerはスキップ
出来上がったらDNS Name(www2-4444444.us-west-2.elb.amazonaws.com、など)と、 Availability Zones(us-west-2a,us-west-2b,us-west-2c、など)を確認しておく。 これらは後々使う。
DNS CNAMEの設定
自分の持っているドメインにELBのDNS Nameを別名(CNAME)で書き込んでおく。 ELBはホストやゾーンを渡り歩くので、AレコードやIPアドレスで指定してはいけない。 私は*.papa.toをもっているので、
IN CNAME www2 www2-4444444.us-west-2.elb.amazonaws.com. (末尾のピリオド.を忘れないこと)
こうしておくと、www2.papa.toは別名でAWSのELBサーバのIPアドレスになるというわけ。 DNSが更新されるまでサイトによっては時間がかかるので、AutoScaling設定前にやっておいた方がよい。
コマンドラインツールのインストールと設定
Webでやる方針なのだが、オートスケーリングだけはツールでしか設定できないので EC2 API Tools(ec2-api-tools.zip)と、Auto Scaling Command Line Tool(AutoScaling-2011-01-01.zip)を 落としてきて、ホームなどで展開し環境変数を整える。私のようにMacOS Xを使っている人はJAVA_HOMEも参考に。
---------.profile-------- export JAVA_HOME=/Library/Java/Home export AWS_AUTO_SCALING_HOME=/Users/papanda/AutoScaling-1.0.61.3 export EC2_HOME=/Users/papanda/ec2-api-tools-1.6.10.1 export AWS_ACCESS_KEY=AAAAAAAAAAAAAAAA export AWS_SECRET_KEY=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB export AWS_CREDENTIAL_FILE=/Users/papanda/.autoscaling export PATH=$PATH:$AWS_AUTO_SCALING_HOME/bin -------------------------
オートスケーリングツールは環境変数ではなく設定ファイルが必要。これもホームに。
-------.autoscaling---- WSAccessKeyId=AAAAAAAAAAAAAAAA AWSSecretKey=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB -----------------------
オートスケーリングの設定
オートスケーリングの設定を開始する。名前はMyLC。
$ as-create-launch-config MyLC --image-id ami-xxxxx --instance-type t1.micro --region us-west-2 OK-Created launch config
image-idに起動したいWebサーバのimage-idを設定する。instance-typeはお金次第だが負荷テストを考えるとmicroが良い。
Malformed input-AMI ami-xxxxx is invalid: The image id '[ami-xxxxxx]' does not exist
というエラーが出た場合、先ほどAMIをセーブしたリージョンを設定すること。
オートスケーリンググループを設定する。名前はMyASG。サーバ台数を調整したい場合はmin-size,max-sizeを調整する。
$ as-create-auto-scaling-group MyASG --launch-configuration MyLC \ --availability-zones=us-west-2a,us-west-2b,us-west-2c \ --min-size 1 --max-size 10 --load-balancers www2 --region us-west-2 OK-Created AutoScalingGroup
この時点でインスタンスが起動し始める。起動しなかったらAMI(VPC)の設定などを確認すること。 また、上記のコマンドラインで以下のようなエラーが出た場合はavailability-zonesとload-balancersに間違いがないか確認すること。
as-create-auto-scaling-group: Malformed input-Launch configuration name not found - null
スケールアップ&ダウンポリシーを設定する。名前はScaleUpとScaleDown(そのまんま)。 どかんと増やしたり減らしたりしたい場合はadjustmentを調整する。
$ as-put-scaling-policy ScaleUp --auto-scaling-group MyASG --adjustment=1 --type ChangeInCapacity --region us-west-2 arn:aws:autoscaling:us-west-2:.......
$ as-execute-policy ScaleUp --auto-scaling-group MyASG --region us-west-2 OK-Executed Policy
$ as-put-scaling-policy ScaleDown --auto-scaling-group MyASG --adjustment=-1 --type ChangeInCapacity --region us-west-2 arn:aws:autoscaling:us-west-2:.......
$ as-execute-policy ScaleDown --auto-scaling-group MyASG --region us-west-2 OK-Executed Policy
コマンドライン作業はここまでで終わり。
アラームの設定
オートスケーリングはCloudWatchのアラームと密接に関連している。 CloundWatch(異常検出) --> AutoScalingが受信 --> ポリシーに従いEC2インスタンスを増減、という手順。
Create Alarm Wizardにはいり、メトリクスビューイングで「EC2: Aggregated Auto Scaling Group」を選択し、 該当のオートスケーリンググループ(MyASG)群から、CPUUtilizationなどのメトリクスを選択して作成する。 Define Your Actionsで、Take actionに 「Auto Scaling Policy」を選択し、Auto Scaling Groupに「MyASG」、 Policyに「ScaleUp(またはDown)」を選択 して登録する。これらは当然ポリシーが作成されていなければ選択できないので、 選択肢に現れなければ設定を見直す。

|
あと、当然しきい値などの条件が異なるので、ScaleUpとScaleDownは別々のアラームで作成すること。

|
オートスケーリングの削除方法
忘れちゃいけないオートスケーリングの消し方。無限に金を取られる。
$ as-delete-auto-scaling-group MyASG --region us-west-2 --force-delete
Are you sure you want to delete this AutoScalingGroup? [Ny]y
OK-Deleted AutoScalingGroup
$ as-delete-launch-config MyLC --region us-west-2
Are you sure you want to delete this launch configuration? [Ny]y
OK-Deleted launch configuration
多少強引ですが以上です。
次回があれば実際の変動具合を見てみましょう。
2013-09-28 Googleハネムーンとな?! [長年日記]
_ [開発][Linux] 実は某アフィリエイトをがんばっていた
サーバをアップグレードして、毎月4000円かかるようになってしまった。金がないのでiPhoneのパケット定額を解除した訳だが、いつまでもパケ無しでいるわけ にもいかないので、某アフィリエイトをがんばっていた。
ドメイン移行してしばらくはすげー順調で「俺って天才かも?」とか勘違いするくらいだったのだが(←プゲラッ)........ある日 突然アクセスが1/12以下に .....色々いじったが戻らぬ。むしろ、いじればいじるほど悪化していく(ような錯覚)悪循環で。
_ [開発][Linux] Googleハネムーンは存在した
今現在もアクセスは戻ってない。さすがに調べたらGoogleハネムーンという単語に行き付いた。http://seo.siyo.org/engine/seo7836/が詳しい。
新しく開設したばかりのサイトが一定期間上位表示しやすい現象
..........それはこういうことですかね。

|
本当に きっかり1ヶ月 で笑った。過大なアクセスがきていたのは私の実力でも、コンテンツが評価されたからでもなかったわけで。しかし...えーと、この名称なんとかならんの? 今年結婚した私にはハネムーンの名称が非常にグッときます。死にたい。
_ [開発][Linux] わかったこと2点
皆さんご存知のように、ここはかれこれ13年くらい維持している独自ドメインなのね。つまり サブドメインであってもハネムーンは存在する という一つの例証として挙げられるでしょう。
あと、コンテンツが少ない場合は全く関係ないようで。それはほぼ同時期にたちあげた検索サイトには全くアクセス来なかったことからも明らかで。
- オリジナルで良質なコンテンツを一時期に大量に用意する
- 継続的に人が訪れるような”しくみ”を作り出す
というのは、世間一般でも言われてることなんだけど、そんな事できる奴は世の中そうそう居ないんじゃないんです?パクり以外で。
サーバ費用くらいは賄いたかった..............
結論:死にます
![[BANNER]](../image/banner.png)
このサーバーをもう12年も維持しているかと思うとめまいがしますよ。
ツッコミ機能は、ハンドル名が完全日本語じゃないと登録できません。
また、本文にURLが含まれていても登録できません。
いずれもSPAM対策です。
![[Panda Papanda]](../image/panda.jpg)
|
訪問者数:(11777+2560143)
- 2013-10-31
- EC2スポットインスタンスを勘違いしていた
- 2013-10-29
- EC2バーサスさくらVPS(何番煎じ?)
- 2013-10-28
- 古いCentOS5のyumが失敗する
- VPS探し中
- 2013-10-22
- さくらのVPSが落ちていて仕事が滞った
- 少しでも安くEC2を借りる方法はないか
- 借りてみた
- 2013-10-08
- Amazon Auto Scalingのパラメータについて考える
- 同じEC2を使っていても....
- 2013-10-04
- Amazon EC2 AutoScaling & Elastic Load Balancer cheat sheet.
- 2013-09-28
- 実は某アフィリエイトをがんばっていた
- Googleハネムーンは存在した
- わかったこと2点
- 2013-08-18
- サーバをさくらVPS SSDプランにした
- tDiaryが動かない.....
- 2013-07-15
- Twitterアイコンパクりを見つけるサイト「顔パク」
- パクリの見つけ方
- 作ってわかったこと